Threat modeling Meta, the Fediverse, and privacy (DRAFT)
DRAFT! Work in progress! Feedback welcome

Last major update July 7 2023. See the update log at the bottom for updates. Thanks everybody for feedback on earlier versions!
One very important piece of feedback I haven't yet incorporated is that it needs a summary ... very true. In the current version, a combination of Today's Fediverse is prototyping at scale and the Charting a path forward sections are the best approximation of a summary – assuming you already know how little privacy there is in most of the Fediverse. If that's news to you, the first section (There's very little privacy in the Fediverse today. But it doesn't have to be that way!) is the place to start.
DRAFT! Work in Progress!
Feedback welcome!
Note to people using assistive technologies: the images aren't final yet, and all the information in them is in the text of the article as well, so I'm holding off on adding detailed alt-text until they're finalized. But I will!
Contents:
- There's very little privacy in the Fediverse today. But it doesn't have to be that way!
- Today's fediverse is prototyping at scale
- Threat modeling 101
- They can't scrape it if they can't fetch it
- Different kinds of mitigations
- Attack surface reduction and privacy by default
- Scraping's far from the only attack to consider
- Win/win "monetization" partnerships, threat or menace?
- A quick note to instance admins
- Charting a path forward
- Recommendations – If you're short on time and just want to know how you can help improve privacy and safety in the Fediverse, there are suggestions here developers, instance admins, journalists, hosting companies, funders, businesses, civil society organizations and anybody who's active in the fediverse today.
There's very little privacy in the Fediverse today. But it doesn't have to be that way!
Meta's potential arrival may well catalyze a lot of positive changes in the fediverses. And changes are certainly needed!
– from In chaos there is opportunity!
As the discussions of Meta's new Fediverse-compatible Twitter competitor Threads highlight, privacy and other aspects of safety are some of those areas where positive changes are certainly needed in the interconnected web of decentralized social networks known as "the Fediverse". Mastodon, the best-known software in the Fediverse, wasn't designed and implemented with privacy in mind – in fact it violates pretty much all of the seven principles of Privacy by Design. Privacy by default? End-to-end security? User-centricity? Uh, no. And it's not just privacy, it's other aspects of safety as well.
We interrupt this blog post for a public service announcement.
Please do not use Mastodon or other fediverse software for confidential or secret information. Don't use Facebook, Instagram, Twitter, or any other social network either. Use Signal or some other encrypted messaging system.
We now return you to your regularly-scheduled programming.
And it's not just Mastodon, the same is true with most if not all the other fediverse software today. Even the underlying ActivityPub protocol that powers the fediverse has major privacy and safety limitations.1 And, you can't have privacy or safety without security and Mastodon et al have a long ways to go in that respect – both in terms of the software and operational security.2
But it doesn't have to be that way!
Even with all of today's software issues, community-oriented instances,2.1 configured with a focus on safety (including privacy) and an emphasis on local conversations, can be more private (and a lot safer) than Facebook or Instagram. Unfortunately, that's very far from the experience for most people in the fediverse. Admins2.2 of most of the largest instances today and choose less-private configurations and run the "mainline" version of Mastodon rather than lother forks (variants) that provide valuable improvements.2.3
The good news is that today's low bar – in the software, at hosting companies, on the instances that haven't turned on settings that would protect people and their data – isn't set in stone. Large instance admins could prioritize privacy and safety more than they do today. So could software developers – and if they do, there are a lot of straightforward changes to the software that could improve the situation. Corporations, governments, and civil society groups looking at the fediverse could also prioritize private and safety ... including funding some of this badly-needed work. And new implementations could focus on privacy and safety from the beginning.
This article looks at privacy, which is just one aspect of safety. Febuary 2024's Steps towards a safer fediverse takes a broader view, and mentions the importance of threat modeling, but doesn't go into remotely this level of detail.
I'll start by making the case that Meta's potential arrival means that it's critical for the fediverse to start focusing on privacy. After that, the bulk of the article focuses on threat modeling, a useful technique for identifying opportunities for improvement, and specifically looks at the threat of Meta getting people's data without consent. Threat modeling can and should also be applied to other aspects of safety (Social threat modeling and quote boosts on Mastodon) and there are lots of potential threats from Meta and a lot of other threat actors to consider but I'm going to focus narrowly here , and keep things at a fairly high level.
I wind up with a section on Charting a path forward, and if you don't want to wallow in the details you can just leap ahead to there. Or if you're short on time and just want to know how you can help improve privacy and safety in the fediverse, skip ahead to the Recommendations for developers, instance admins, journalists, hosting companies, funders, businesses, civil society organizations and anybody who's active in the fediverse today.
Today's fediverse is prototyping at scale
Meta's new Threads offering increases the urgency of addressing the fediverse's longstanding privacy issues; even though it's not compatible with ActivityPub yet, according to Instagram CEO Adam Mosseri it will be "soon". Of course, Meta's a threat in many other ways as well: to the safety and mental health of many people in the fediverse, to many marginalized communities who are trying to make a new home there, to democracy.... As Seirdy says in De-federating P92, "Of the reasons to resist a Facebook/Meta presence in the Fediverse, privacy is relatively low on the list."
That said, the privacy aspects are important too. For one thing, if Meta does indeed follow through on its plans to work with Mastodon instance admins and others "partners", people who trying to avoid harassers or stalkers on if their posts or even their account names get to Meta. And more generally, people in the region of the fediverse that's not Meta-friendly will need stronger privacy protections to protect their data. Of course Meta's far from the only threat to privacy out there; but changes that reduce the amount of data Meta can gather without consent will also help with other bad actors.
TODO: INCORPORATE Why just blocking Meta’s Threads won’t be enough to protect your privacy once they join the fediverse HERE AS AN EXAMPLE.
And more positively, there's also a huge opportunity here. Privacy's even worse on Facebook and Instagram than it is in the fediverse. Their software is the opposite of Privacy by Design – everything about it is designed to track your every move and encourage you to give them as much data as possible and feed their monetization algorithms. People don't like that but accept it because (for many) there aren't any other good options. If the fediverse can provide a more private alternative, that will be hugely appealing to a lot of people.
Any way you look at it, now's a good time for the fediverse to take privacy more seriously.
And not just privacy, of course. One way to look at today's Fediverse is as a prototype at scale, big enough to get experience with the complexities of federation, usable enough for many people that it's enjoyable for social network activities, but with big holes including privacy and other aspects of safety, equity, accessibility, usability, sustainability and ....
Now's the time to get beyond the prototyping stage.
One path forward is to evolve today's implementations and addressing problems incrementally. From this perspective, threat modeling can help identify low-hanging fruit to make more rapid progress in the short term as well as highlight important areas where there aren't any good short-term answers yet.
Threat modeling's also useful for the complementary path of new implementations that start with a focus on privacy by design (and design from the margins, and software engineering best practices, and safety, and equity, and accessibility, and ...).
So let's get to it! Or, if you prefer, skip ahead to the section on Charting a path forward and the summary of Recommendations in the appendix, and then come back to the details.
Threat modeling 101
Social threat modeling applies structured analysis to threats like harassment, abuse, and disinformation. You'd think this would happen routinely, but no.
– Social threat modeling and quote boosts on Mastodon
What are the specific ways Meta is a threat? What can we do in response? Threat modeling is a structured way to explore those questions. In this post I'm going to focus on privacy at the software and system level, but it applies to all kinds of threats. Social threat modeling and quote boosts on Mastodon the post about quote boosts and A trip down memory lane, for example, look at applying threat modeling to harassment. Digital Defense Fund's Threat Modeling and EFF's Your Security Plan have some good techniques for individuals to do threat modeling to protect their data privacy.
Let's start by taking the perspective of a "threat actor" like Meta and looking at potential goals or likely consequences of their hostile actions. A complication is that we don't know just what Meta's goals are for the fediverse, and we don't know just how they'll approach it. Still, we can make some assumptions based on their past behavior and business models, as well as the information that's been reported to date.
Historically, Meta's business is monetizing data gathered without consent. Today, they mostly do that by selling ads and the ability to promote posts.3 They even gather data of people who don't have Meta accounts to create "shadow profiles" – and gather data from other sites about people who do have Meta accounts to better target them.
So if Meta does in fact come to the fediverse, it's extremely likely that they'll try to collect data without consent from people on other fediverse instances. That's what they always do! How might they approach it here?
To make it concrete, here's a partial and very simplified threat model. This only scratches the surface; what's really needed is an organized social threat modeling effort – and that's going to require funding. Still, even with its limitations, as you'll see, it highlights some specific ways privacy on the fediverse could be improved – as well as potential additional privacy threats from Meta that haven't gotten a lot of discussion yet.
UPDATE, July 20: Renaud Chapaud's just-published Evolving Mastodon’s Trust & Safety Features introduces new potential threat vectors that still need to be incorporated in this model. What if Meta runs a "trusted" third-party provider that scans for spam and hate speech, and encourages instances send them all the posts (including private posts and DMs, which also need to be checked) along with additional informaiton, potentially including IP addresses? At least in the US, Meta would have wide latitude to use that data for other purposes as well. Dan Supernault's proposal for centralized abuse and spam checking has similar issues. Of course, others might provide those services as well as (or instead of) Meta, introducing similar threats, so this is another example of how looking at the threat from Meta helps mitigate other threats a well.
Advocates of federating with Meta often make arguments like "Meta can already get all the data the want by scraping web pages." In Project92 and the Fediverse - A Smarter Battle Plan to Protect the Open Social Web, for example, Tim Chambers dismisses the argument that people should be concerned about Meta's data scraping by saying "defederation does virtually zero to avoid any big tech entity scraping all the Fediverse public social graph today." To be clear, as Esther Payne discusses in Consent and the fediverse, this is not actually a compelling argument for sharing people's data with Meta. Not only that, it's an exaggeration; even with all of today's weaknesses, there's lots of valuable data that can't easily be scraped. As Daniel Solove and Woodrow Harzog note in their recent The Great Scrape: The Clash Between Scraping and Privacy, " the public availability of scraped data shouldn’t give scrapers a free pass."
Still, there's certainly an important kernel of truth in this argument: a lot of fediverse data can easily be scraped today, and bad actors are almost certainly doing it. And Meta's admitted scraping data in the past, so they certainly might try.
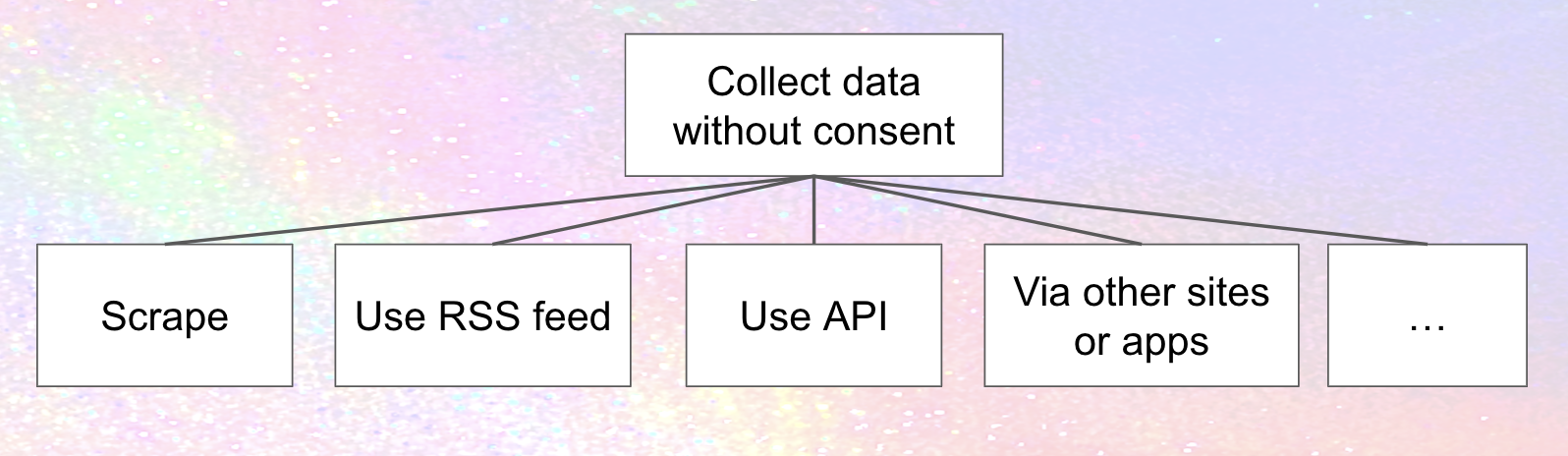
Of course, scraping's far from the only realistic privacy threat from Meta. The simplified diagram above also includes a couple of others:
- Mastodon provides RSS feeds for every profile, containing all the public and unlisted posts. So does other fediverse software (although I'm not sure about unlisted posts). RSS is a good thing! But it can also be used for collecting data.
- Instances running fediverse software - just like any other web service out there – provide application programming interfaces (APIs). APIs are also good things! Apps are built on top of APIs; instances communicate with each other using APIs. But APIs can also be used for other purposes ... like collecting data.
- Meta might get the data from other sites or apps. Hospital Websites, Tax prep websites, mental health charities, and pretty much everybody you can think of share sensitive data with Facebook without people's consent, so it's certainly imaginable that Meta would try to get its "partners" in the fediverse to share data without consent. Of course, a lot of this sharing is illegal, leading class action suits and FTC settlements, and Meta says it's not their fault (it never is). Still, for those of us who don't want our data going to Meta, that doesn't make it any less of a threat.
UPDATE: GunCheoch pointed out to me that this draft ignores relays which are also a path for Meta (or anybody else) to get data view other sites. Quite right, and that needs to be reported!
There are a lot more privacy threats of course (that's what the "..." in the image is supposed to indicate), which is why a funded systematic threat modeling effort is so critical, but you get the idea.
We'll come back to those other threats below let's start by digging into scraping in a little more detail - and switch our perspective to how to prevent it.
They can't scrape it if they can't fetch it
TODO: update scraping discussion based on the joint statement on scraping by ICO et. al., Web Scraping for Me, But Not for Thee, and Block the Bots that Feed “AI” Models by Scraping Your Website, and The Great Scrape: The Clash Between Scraping and Privacy
Web scraping works just like web browsing: given a URL (link) to a web page, fetch the HTML contents of the web page. Instead of just displaying it the way a browser does, scraping software analyzes it and extracts the data from it. When you share a link from another website to Mastodon or other fediverse software and it automagically includes the headline and image, that's a very simple example of web scraping, and one that's widely accepted as legitimate.
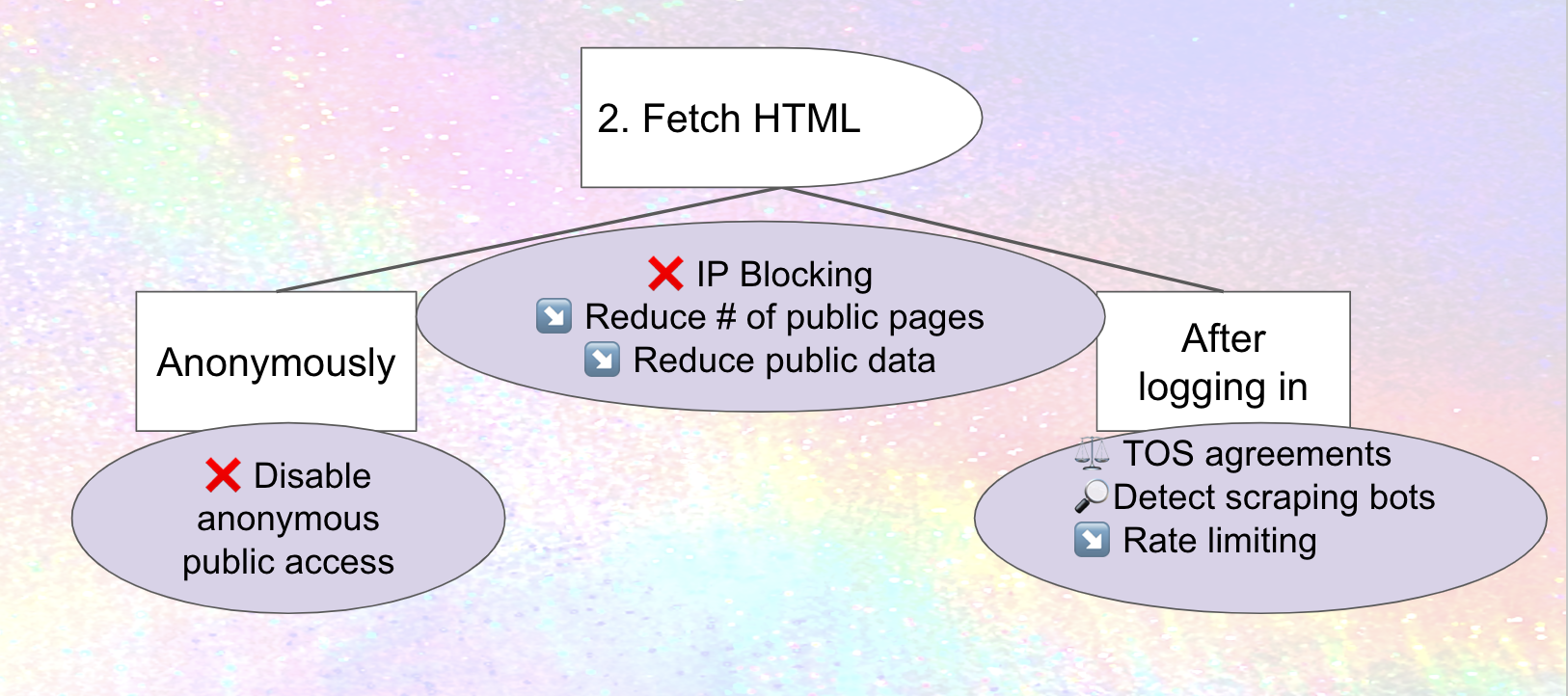
Here's a simple visual representation.
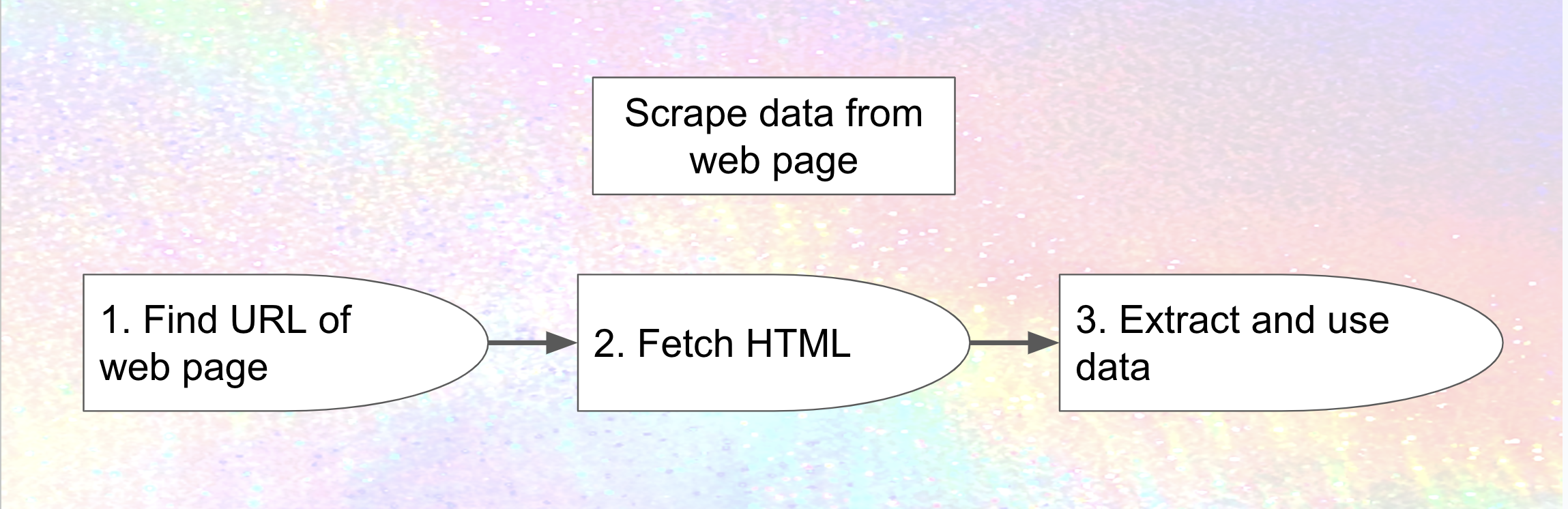
So one way to prevent scraping is to prevent potential scrapers from fetching the HTML of the web page.
Unfortunately, this is easier said than done. For one thing, scrapers aren't the only ones who fetch HTML; so do legitimate users, via their browsers, whenver they're looking at anything on the fediverse. So we need find restrictions that will be roadblocks to their scraping, but don't cause so much inconvenience to legitimate users that they're impractical. Not only that, Meta and other scrapers can be very cunning, and will adapt their tactics to whatever we do, so we'll need to try to anticipate their countermeasures.
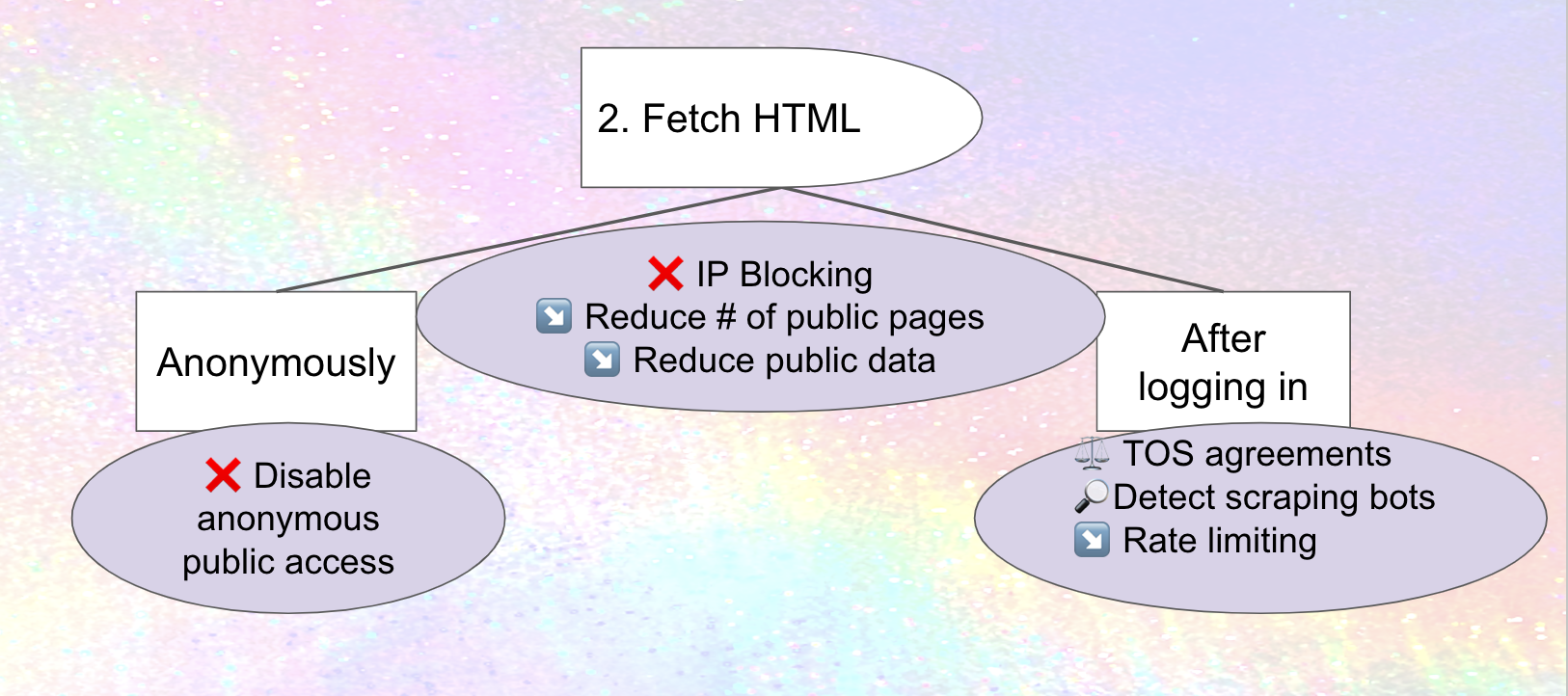
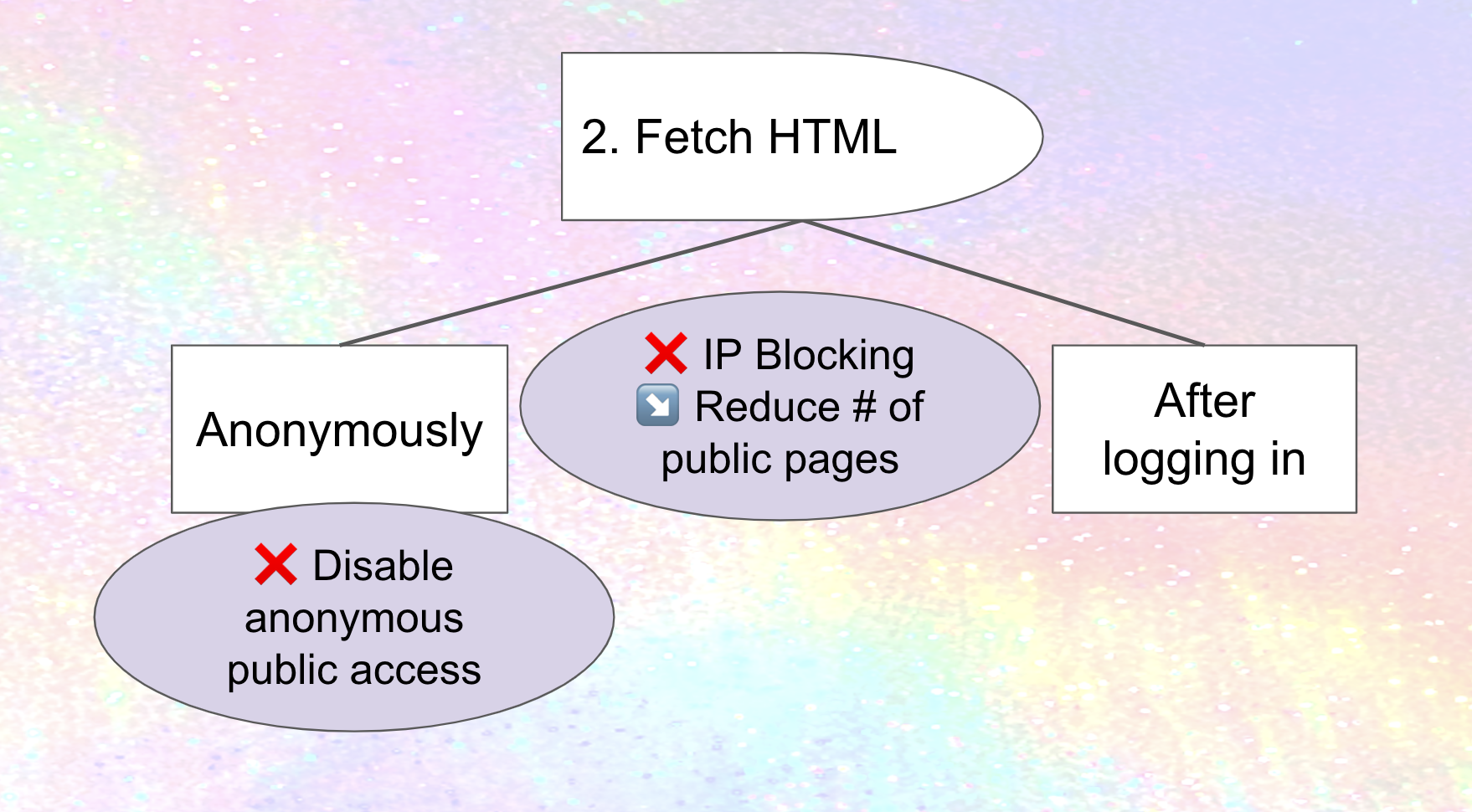
IP blocking, prohibiting access to your site from a range of internet addresses, is one straightforward approach to preventing scraping (although may have downsides as well). If Meta only scrapes from a subdomains of threads.net, or a predictable set of addresses, IP blocking those could stop spreading cold. Mastodon's documentation describes how IP blocking can be done at the firewall level, which makes sense, but there are probably ways to streamline it, existing tools and processes to leverage and package, and potentially new tooling for sharing IP blocklists. Do hosting companies provide these services to people or organizations who are hosting there? What are the downsides of IP blocking with email, and are there ways to avoid or at least mitigate them in the fediverse? These are all areas for improvement for fediverse software today – and one that builds off work that's already been done on projects like The Bad Space and Oliphant Blocklists.
Recommendation: educate people on (and potentially package) existing processes and tools for IP Blocking, integrate with suspend/limit federation-level processes and infrastructure, and potentially develop new tools and look for ways to address downsides.
Then again Meta could get around this easily enough in a couple of ways. They could hire somebody else to do the scraping for them, as they have in the past. Or just like spammers dodging email blocklists, they could potentially rotating a lot of different domains and addresses in different ranges. For that matter, Meta could enlist some of their "partners" to run their own scrapers (perhaps to help them "monetize" more efficiently). So if they want to scrape, IP blocking by itself won't stop them.
Disabling anonymous access to web pages (which means only logged-in accounts can look at them) is a complementary approach. Once again, countermeasures are possible: Meta or its "partners" could use RSS instead, so we'll need ways of plugging that hole as well. Or, they could conceivably create accounts on anti-Meta instances and secretly use them to scrape, so we'll need to think about counter-measures for scraping from logged-in accounts as well. Still, it's a useful hurdle.
Update, August 10: asking users to share their API access token is an alternative to creating new accounts for scraping. Fediseer already does this, and the fedibuzz pseudo-relay is currently requesting token donation in response to Mastodon 4.2 cutting off anonymous access to the streaming API.3.8 The downside of token donation is that it also gives access to the DMs of anybody who donates a token, so I'd hope that people would think twice before going this route with Meta, but you never know.
Mastodon actually does provide a setting that disables anonymous access to the web pages of all profiles, timelines, and individual statuses on a site, although I'm not sure how usable it is in practice.4
Recommendation: ensure there's a usable way for an instance to disable anonymous access to all profiles, timelines, statuses, images, etc
Even if it worked, though, blocking all public access has a huge cost in many cases. I want the Nexus of Privacy's profile, and most of the posts I make from that account, to be visible to people who aren't logged in – even if that leaves it at risk of being scraped by Meta. Many other content creators, politicians, journalists, influencers, and celebreties also want at least some of their social media activity to be public. Most instances will want to support that. Still, individuals might want to make different choices, so individual accounts the ability to disable anonymous access to their statuses and timelines would be very valuable as well.
Recommendation: provide individuals a usable way of disabling anonymous access to their profiles, timelines, statuses, images, etc.
Even if somebody wants some of their data to be public, that doesn't mean everything has to be. Mentioned-only posts (sometimes call direct messages) and followers-only posts, neither of which are visible to anybody who's not logged in, are good examples of this already supported by most fediverse software. But that's only the tip of the iceberg. Mastodon forks (variants) like Glitch-soc and Hometown, as well as compatible software like Akkoma, Misskey, and Calckey, have local-only posts. Friendica and Hubzilla have private groups, only visible to members of the group. Hometown maintainer Darius Kazemi has estimated that 70% of Hometown activity is local-only, and while that's not likely to be the case for more publicly-oriented sites (infosec.exchange admin Jerry Bell says that he rarely sees them), this would still be a good step forward.
What about unlisted posts? Today, despite their name, they're essentially public: they don't appear on timelines and hashtags, but do appear on profiles, and anybody can view them anonymously. That could change, for example allowing instances or individual users to require login. Of course, changing this would have broad implications, and for it to be effective ways would also have to work with older versions of the software, so maybe it would be better to introduce a new visibility level – something like "federatable but not viewable to people who aren't logged in". In any case, it's worth thinking about.
And there's also room to explore additional visibility options that cross instance boundaries. Akkoma, for example, has the concept of a "bubble" of instances that share boundaries. Is bubble-only visibility a useful concept? So this highlights another way to make thing harder for Meta (and other scrapers).
Recommendation: Reduce the number of public pages.
- Increase use of local-only posts, private groups, and other existing mechanisms that limit scrapability
- Consider requiring login to view unlisted posts.
- Investigate new visibility levels like "federatable but not viewable to people who aren't logged in", "viewable only to people logged into instances we federate with", "viewable only to people logged into instances that don't federate with Meta", and "viewable only to people in the same fedifam or caracol" (group of aligned instances, described below)
- Provide an option for private profiles
Here's a visual representation of what we've discussed so far. Mitigations (in the circles) are marked with an ❌ if they prevent the attack, or a ↘️ if they reduce the severity.
Different kinds of mitigations
All the potential mitigations we've talked about so far have been technology-based and focused on preventing scraping, but that's not the only approach.
Legal protections are a complementary tactic. They won't necessarily deter a company like Meta that frequently ignores the law, relies on their hundreds of lawyers to try to find loopholes and string the cases along, and budgets for paying huge fines as a cost of doing business. Still, as data protection agencies in Europe continue to bring pressure on Meta – and laws like Illionois' BIPA and Washington state's new My Health My Data allow individuals to sue entities of any size for privacy violations in some situations – they could have enough of an impact by increasing the likely cost of scraping that Meta (or some of the partners they attempt to enlist) decides it's not worthwhile.
I'm not a lawyer, so please don't take this as authoritative, but my impression is that scraping public profiles, timelines, statuses, and images is usually legal under today's laws (although their are exceptions – Clearview AI's scraping, for example, has led to it being banned from selling its facial recognition software in country after country, including the US). But when somebody creates an account on a fediverse instance, they have to agree to the Terms of Service (TOS), which could potentially have prohibitions on scraping. Ryanair won a 2015 case in the EU and its TOS seems to have played a big role in it.
So there may be possibilities here. Then again, this approach could have downsides as well. I'm not a lawyer, but there are plenty of them on #LawFedi – and for that matter plenty of them at organizations that are deeply suspicious of Meta and contemplating being on the fediverse. It's worth talking to them about this!
Recommendation: investigate potential Terms of Service provisions limiting data harvesting, such as prohibiting accounts from doing automatic scraping and/or sharing data with Meta
As well as trying to prevent a certain kind of attack, mitigations can also focus on detecting it or limiting the damage. For example:
- Analyzing account activity could detect scraping patterns (although scrapers can modify their software to avoid this)
- Rate limits can cut down on how much scraping is done, although potentially also interfere with legitimate activity
Here's the diagram including these, and a sneak preview of another mitigations I'll discuss in the next section. I'm using a couple of new icons here: ⚖️ (the scales of justice) indicate legal protections, and 🔎 indicates a mitigation focusing on detecting attacks.
Attack surface reduction and privacy by default
Reducing the number of public web pages is an example of a powerful technique called attack surface reduction. The underyling idea is simple: the less data that's out there, the less there is for Meta – or any other threat actor – to gather. Okta's What is an Attack Surface? (And How to Reduce It) and Microsoft's Understand and use attack surface reduction (ASR) are intros to attack surfaces from a security perspective, and it's easy to see how it applies to privacy as well.
Mastodon's "Hide your social graph" preference setting is a good example of this. If you turn it on, your following / followers lists are no longer visible in your profile. This data is very valuable to Meta – it's great for targeting ads – but it's also very risky for many people, including immigrants, activists, and people seeking reproductive and gender-affirming health care in states where it's illegal and anybody helping them. So being able to opt out and remove it from your profile is a very good thing.
Of course, from a privacy perspective, it would be even better if "hide your social graph" was the default and you had to opt-in to share it. That way, people would be protected from letting Meta scrape this risky data unless they explicitly decide they want Meta to have that information. And this is far from the only situation where the default leaves data exposed. By default, Mastodon allows anybody to follow you without checking for approval; which means they can get access to followers-only posts.
Recommendation: "Privacy by default": Set defaults so that people start with stronger privacy protections, and can then choose to give it up.
And while it's great that Mastodon gives people the option of whether or not to show their social graph, it doesn't offer the same flexibility with other data. For example, as far as I know, there's no way to make my pronouns visible to people who are following me or people on my local instance but not to the entire world? So it's worth making a systematic effort to analyze how much of what's visible today really needs to be there.
Recommendation: Reduce the amount of data that's in public pages, including differentiating between what's shown at different levels of visibility
Scraping's far from the only attack to consider
Let's briefly discuss the other three threats we touched on earlier.
At least on Mastodon, there's no way to disable RSS feeds. Hometown and GoToSocial, by contrast, take a "privacy by default" approach of turning them off unless people choose to enable them. Other fediverse software should follow their lead. An attack surface reduction approach of reducing the amount of data that's available via RSS feeds is a complementary approach. For example, unlisted posts are currently in the RSS feed; removing them (or introducing a setting that defaults to leaving them out) is an easy improvement. And there may well be other opportunities.
Recommendations:
- Provide control for individuals and sites to determine whether RSS feeds are available, and investigate options to reduce information in RSS feeds
For API access, the existing "Authorized Fetch" (also sometimes called "Secure Fetch") mechanism prevents API access from blocked instances; What does AUTHORIZED_FETCH actually do? is a good overview. Fediverse instances that prioritize safety already have it turned on because it reduces dogpiling and other kinds of harassment; others should turn it on ASAP. And in another good example of "privacy by default", software platforms and hosting companies should make it the default going forward.
Combining Authorized Fetch that with shared up-to-date blocklists that include all of Meta's instances could prevent Meta-run instances from directly accessing data via an API. But Meta's decentralized approach could well mean that their instances are hosted under lots of different domains,5 so it's not clear what infrastructure will be needed to do it effectively – or if it's even feasible. Most fediverse software can be run in "allow-list" federation mode; on Mastodon, for example, it's the LIMITED_FEDERATION_MODE setting.
However, relatively few instances take this privacy-friendly approach today; indeed, Mastodon's documentation misleadingly describes it as "contrary to Mastodon’s mission of decentralization." To date, relatively little work has been done developing processes and tooling for making allow-list approaches work well, or looking at other alternatives besides pure blocklist or allow-list approaches. So this is an area where investigation is needed ... and there are a lot of interesting complementary possibilities here. For example:
- Peertube's manual approval of federation requests (similar to the "approval first" mode described by vitunvuohi here) and ability to follow a list of instances to approve
- the "letters of introduction" Erin Shephard describes in A better moderation system is possible for the social web, applied to federation instead of individual following
- Darius Kaziemi's "threaderation" (which is a bit more restrictive than the current "silencing" approach).
- ophiocephalic's proposal of "fedifams", a family or alliance of instances where admins could deliberate together on blocklist/allow-list decisions, and a broader moderation council with a representative from multiple fedifams
- Kat Marchán's suggestion of "caracoles", concentric federations of instances that have all agreed to federate with each other, with smaller caracoles able to vote to federate with entire other caracoles.
As mentioned above that fedifams and caracoles could also be potential post visibility boundaries, providing more alternatives to fully public posts.
Apps can also get data via APIs. Suppose Threads lets people login to their accounts on other instances as well. If I've blocked Meta, but somebody I'm friends with in the fediverse uses Meta's app to log into their account and view my status, could the data get to Meta? Without doing a full analysis, my guess is probably yes. If so, what are the countermeasures – for example, allow-lists for apps?
Recommendations:
- Enable "Authorized Fetch" on current sites, and make it the default setting in software releases and at hosting sites.
- Investigate shifting to allow-list federation, and look at alternative approaches like "approval first" federation.
- Investigate tooling for and feasibility of blocklist of Meta's instances if there are a huge number of them hosted on different domains
- Look at potential app-based dataflows and potential counter-measures.
Win/win "monetization" partnerships, threat or menace?
The indirect approach, where Meta enlists instances that federate with them to harvest (and "monetize") data from people and instances who don't, opens up new cans of worms. If Meta really does pursue a decentralized strategy (still a big open question) this is new ground in a lot of ways, and a lot will depend on the implementation, so right now this section has a lot more questions than answers. They're very important questions, though, because the answers to these will have a big impact on how people in the different regions of the fediverse will be able to interact.
If I'm on an instance that blocks a Meta instance, you're on an instance that federates with them, and somebody on a Meta instance is following you, what happens when you boost, quote boost, favorite, or reply to my status? As Mastodon Migration's post (based on input from Calckey maintainer Kainoa as well as infosec.exchange admin and security expert Jerry) shows, it's complex, and the answer is different for different software (and depend on whether instances are running Authorized Fetch). So this is a place where detailed analysis is needed.
And suppose instances that federate with Meta decide to take advantage of Meta's services to recommend content (and/or target and serve ads)? Even if I've blocked Meta, if you're following me from an instance federated with Meta, the software might send my data to them to help recommend better content for you (and/or better target you) ... and once they've got it for one purpose, who knows what they'll use it for. Is there a way to prevent that from happening?
Meta's implementation, and the legal agreements they put in place for instances that federate with them, are both wildcards at this point. It'll take a while to analyze the implementation even in the very unlikely event they open-source everything and provide a good architecture and design documents, so the best course of action for now is to take a "privacy by default" approach here of transitive defederation: defederating Meta, any instances that federate with Meta directly or indirectly.
That said, this is a very blunt hammer. Are other approaches possible? For example, suppose there was a way for an instance to say "I'll only federate with a site if their privacy statement legally commits them to not sharing any data they receive from my instance with Meta, or with any instance that will share it with Meta" – and the software provided the functionality that could make that commitment real? Is there a role for "bridge" instances, not federating with Meta and somehow allowing people from both "free fediverse" and Meta-friendly instances to communicate while limiting the data that could flow back to Meta?
Recommendation: initially adopt the "privacy by default" approach of transitive defederation to protect against indirect data flows via Meta-federating instances while analyzing implementation and policies and investigating more flexible alternate approaches
A quick note to instance admins
Now's a crucial time for instance admins to think about their goals and responsibilities. Are you committed to providing a private and safe experience for people in your community? If so, then show your commitment by shifting your thinking to "privacy by default", and making sure your configuration settings (and software choices) reflect that. Of course, no principle is absolute, so there may well be tradeoffs; and these changes can't necessarily be made overnight. Still, if this the direction you want to go, taking some initial meaningful steps and announcing a plan and timeframe is a good way to demonstrate that you really mean it.
If that's not the direction you want to go, well, that's also a good thing to let people in your community know so they can make a good decision about whether it's the right instance for them.
Threat modeling's especially important for admins who are considering federating with Meta. For one thing, one of the arguments in favor of federation at the instance level is that people on the instance have the "agency" of defederating themselves. But will that defederation actually protect them, or still leave them at risk? It's a hard question to answer until we see the actual implementation, but based on what we know today assuming that'll be the case seems overly optimistic.
Not only that, if you can't prevent some of the indirect attacks discussed in Win/win "monetization" partnerships, threat or menace?, then instances that don't want anything to do with Meta will have to defederate from you as well – meaning that people on your instance can't talk to their friends elsewhere in the Fediverse.
It's also important to model some of the other threats that are beyond the scope of this article. For example, a lot of LGBTQ+ people are concerned that instances federating with Meta will put them at risk. It's not enough to dismiss this threat by saying "we have tools to prevent this." If you want to ensure people on your instance are safe – or avoid endangering people on other instances – more detailed analysis is needed.
And finally, if you're an instance admin who's advocating working with Meta as long as it doesn't put people on your instance at risk, and you're not currently taking steps to provide better privacy safety to people on your instance, ask yourself why people should trust your evaluation of what does or doesn't put people at risk.
Charting a path forward
One of the interesting things about the recommendations here is how many of them are straightforward: changing defaults, using and improving existing features, mainline Mastodon and instance admins adopting features like local-only posts that have long been implemented in forks (and other fediverse software). Most of what listed here helps protect against other bad actors besides Meta, and much of it helps with safety as well, so these improvements have been needed for quite a while. They just haven't been prioritized.
It's possible that Meta's arrival will lead to the current forks taking privacy and other aspects of safety s to date changing their attitudes, and changing their priorities. Then again, Meta's arrival will also require a lot of other work – scaling, support for whatever win/win monetization Meta's offering, working on the next version of ActivityPub (which will surely need significant improvements to deal with anything on the scale of threads), and ensuring that instances that want to federate can meet other whatever standards Meta requires. So it's also possible that privacy will continue to take a back seat in mainline Mastodon and other platforms.6 If so, it's a good time for forks that prioritizes privacy and safety. And while I know less about other fediverse, the same dynamics may play out there as well.
Recommendation: Create forks that prioritize privacy and safety if mainline Mastodon (and potentially other platforms) continues not to
Of course, even though many of these recommendations are straightforward, there are a lot of them – some of which (like moving to "privacy by default" and getting away from a federate-by-default approach) are a chunk o' work. Not only that, several of the recommendations are to "investigate" potential approaches; and, not to sound like a broken record, this high-level discussion here only scratches the surface and only for this one threat, so what's really needed is a systematic threat modelling effort. And new implementations, designed with privacy and safety in mind, need resources as well.
All of that's going to require funding.
As Afsenah Rigot discusses in Design From the Margins, centering the marginalized people directly impacted by design decisions leads to products that are better for everybody. That's especially important for threat modeling. So equity and diversity needs to be a key consideration in terms of who gets funded to work on these projects – something that hasn't historically happened on Mastodon.
The good news is that there are plenty of potential funding sources who see Meta as a threat, and some of them have decent budgets. Companies like Fastly and Wordpress who are looking at the fediverse have a lot to lose if it winds up dominated by Meta and surveillance capitalism business models. Responsible companies and governments who are considering partnering with Meta have an interest in making sure that they don't getting coopted in (potentially-illegal) data harvesting – or disinformation broadcasting. Many civil society organizations also see Meta as a huge threat. So do inviduals, so crowdfunding's an option as well.
- Pursue funding from anti-surveillance-capitalism companies, civil society groups, and crowdfunding to allow more detailed analysis, design, and rapid implementation – and ensure that the funding is directed in a way that increases equity and diversity.
Who knows, maybe the fediverse as a whole isn't ready for this yet, and it'll continue to stay at the prototyping stage for a while more. Even if that happens, the kind of informal threat modeling I've done here can still be useful to instances that want to insulate themselves from Meta's threats to the extent that they can, platforms that want to prioritize making improvements with their existing resources, and new implementations that want to do better.
With luck, though, Meta's arrival will be the kick in the pants the fediverse needs to shift modes and start taking privacy and other aspects of safety (and equity and accessiblity and usability ...) seriously – and approach it in a way that also improves equity. The opportunity's certainly there!
Appendix: Short-term recommendations for improving privacy of existing fediverse software
This section pulls together the recommendations scattered throughout the article combining a few similar ones in the process and organizing them into categories.
July 7: currently in the midst of an update, so some minor differences between this and recommendations in the article still need to be synced up.
Anybody who's active in the fediverse today.
- Ask your instance admin to provide better privacy and safety – you can point them to the Instance Admins recommendations below. If they say no, and don't have good reasons, consider voting with your (virtual) feet and moving to another instance.
- Let the developers of the software know that you care about privacy and safety and ask them to prioritize improving it.
- If you're running a single-person instance, see the recommendations for instance admins – including turning on Authorized Fetch (you may need to ask your hosting provider to do it for you).
Journalists
- Reject the incorrect and misleading talking point that there's no privacy harms in instances federating because they can (supposedly) already access all the data on the fediverse. Even if it were true (which it's not), as Esther Payne discusses in Consent and the fediverse, it wouldn't be a good argument; and, it takes today's low bar as a given.
- Highlight that until we know the details of Meta's federation plans – including technical solutions and legal agreements – and how current fediverse software will evolve, instances planning on blocking from Meta may well also have to do "transitive blocking" and all instances that federate with Meta in order to keep their community's data from being gathered without consent.
Instance admins
- "Privacy by default": Set defaults so that people start with stronger privacy protections, and can then choose to give it up.
- Initially adopt the "privacy by default" approach of transitive defederation to protect against indirect data flows via Meta-federating instances while analyzing implementation and policies and investigating more flexible alternate approaches
- Enable "Authorized Fetch" on current instance, and make it the default setting in software releases and at hosting sites.
- Consider shifting to allow-list federation or (if your platform supports it) other approaches such as "approval first" federation. If your platform does't support it, ask them to add it – even if it's not right for you, it can help other instances protect themselves.
Hosting sites
- "Privacy by default": Set defaults so that people start with stronger privacy protections, and can then choose to give it up. For example, make "Authorized Fetch" the default setting, and ensure documention explains it well.
Developers and fediverse software projects
Note: these should be reordered!
- Press the project leaders to prioritize privacy and safety in their planning. If they don't consider voting with your feet and creating a fork that prioritizes privacy and safety (as well as equity, usability, onboarding and all the other issues that need to be prioritized).
- "Privacy by default": Set defaults so that people start with stronger privacy protections, and can then choose to give it up. For example, make "Authorized Fetch" the default setting, and ensure documention explains it well.
- Provide a usable way for instances and individual users to protect all profiles, timelines, statuses, images, etc from anonymous access.
- Reduce the number of public pages and the amount of data in them, including supporting private profiles; increasing use of non-public visibility like local-only posts; investigating new visibility levels like "within the same fedifam or caracol", "viewable only to people logged into instances that don't federate with Meta", differentiating between what's shown at different levels of visibility, and (potentially) requiring login to view unlisted statuses
- Provide control for individuals and sites to determine whether RSS feeds are available, and implement an option to remove unlisted statuses from RSS feeds
- Educate people on (and potentially package) existing processes and tools for IP Blocking, integrate with suspend/limit federation-level processes and infrastructure, and potentially develop new tools and look for ways to address downsides.
- Develop processes and tooling for blocking Meta instances and all instances that federate with them. For example, extend nodeinfo to have a field with an instance's policy towards Meta (transitively block, block but federate with instances that federate with Meta domains, federate with Meta domains). Investigate solutions for blocklists Meta and federating-with-Meta domains (taking into account that there are likely to be a huge number of them hosted on different domains), and for allow-lists for instances that don't share data with Meta
- Investigate shifting to allow-list federation, and look at alternative approaches like "approval first" federation.
- Look at potential app-based dataflows and potential counter-measures, possibly including allow- and block-lists for apps as well
- Pursue funding from anti-surveillance-capitalism companies, civil society groups, governments, and crowdfunding to allow more detailed analysis, design, and rapid implementation of privacy and safety features – and ensure that the funding is directed in a way that increases equity and diversity.
Business, government agencies, civil society organizations, and funders:
- Fund (and contribute staff time to) forks and new projects that prioritize privacy and safety (as well as equity, usability, onboarding and all the other issues that need to be prioritized).
- Staff sand fund safety, security, and privacy work including threat modeling – and make sure the funding is distributed in ways that increase equity and diversity.
Notes
1 Christine Lemmer-Webber (who co-authored the spec) says that from a security and social threat perspective, "the way ActivityPub is currently rolled out is under-prepared to protect its users." In ActivityPub: The “Worse Is Better” Approach to Federated Social Networking, Ariadne Conill describes ActivityPub's approach as prioritizing other concerns over safety, and the same's just as true for privacy. ActivityPub's weaknesses make it especially vulnerable to an "embrace and extend" attack where Meta introduces proprietary solutions that are genuine improvements over the standard.
2 Dan Goodin's How secure a Twitter replacement is Mastodon? Let us count the ways is a good overview of some of the issues and the low current bar, like last fall's bug that let people steal passwords by injecting HTML and configuration error that left private photographs from hundreds of instances open to the web. As I was writing this post, the admins of anarchist instance Kolektiva posted an alert that an unencrypted copy of their database had been seized by the FBI.
2.1 An "instance", also a server, is a site running Mastodon, Misskey, Pixelfed, or any other fediverse software.
2.2 Instance admins typically are responsible for configuring the software and setting the sites policies. Many also install, maintain, and update the software, although hosting companies such as masto.host offer those services, so are attractive options for smaller instances or instances whose admins don't have Linux sysadmin skills (or like me have basic skills but hate sysadmining).
2.3 In the open-source world, a "fork" is a variant of a code base run as a separate project. Glitch-soc and Hometown, both of which support local-only posts, are two popular Mastodon forks. Many Mastodon innovations were first developed in forks and then adopted by the mainline; "exclusive lists", coming in the next version, was originally developed by Hometown. Sometimes, though, the mainline decides not to adopt functionality from forks.
3 They're also exploring other revenue models including subscriptions (like Instagram Plus) and an app store in th EU (with the Verge rather hilariously reporting that "at least initially" Meta isn't planning on taking a cut of of in-app revenue, as if they won't change that at the drop of a hat as soon as they decide it makes sense). These are still fairly small contributors to their revenue stream, however, and in any case are also likely to leverage Meta's competence of collecting data without consent.
3.8 Thanks to Vyr Crossont for pointing out Fediseer and Fedibuzz.
4 The setting is called DISALLOW_UNAUTHENTICATED_API_ACCESS. What does AUTHORIZED_FETCH actually do? includes a good short discussion However, the article warns that this setting blocks anonymous access to everything, including the instance's "About" and registration pages. If so, turning it on makes an instance useless for people who don't already have accounts (and could potentially violate laws requiring an Impressum or publicly-posted privacy policy). Bummer. I'm not completely sure this is always true, however; I've seen some sites that appear to block not-logged-in access to statuses and profiles, while still allowing access to the site's about page. I'm not sure if it's this setting or another.
5 Especially if they offer individuals the ability to have their account on their own domain name as part of a $100/year "threads plus" package, or bundle it and use it to increase adoption of Insta Plus, or whatever. Even if they don't go that far and only offer it to a list of partners – celebrities, sports teams, politicians, media outlets, tech pundits, etc – who want to host their communities, there will still be lots of domains. Darnell Clayton's Facebook Fears The Fediverse. Here’s How Instagram Will Try To Conquer It (EEE!!!!) has some interesting thinking on these kinds of scenarios.
6 As The Gibson (mayor of hackers.town) pointed out to me, platforms that aren't taking security and privacy considerations seriou sly need to be treated as a possible supply-chain attack at this point.
Update Log
September 2024: start updating terminology to align with the Terminology section of September 2024's I for one welcome Bluesky, the ATmosphere, BTS Army, and millions of Brazilians to the fediverses! (although it's still a work in progress), added links to Steps towards a safer fediverse and The Great Scrape: The Clash Between Scraping and Privacy
August 24 2023: add TODO with links on scraping.
August 10: add link to fedifams and caracoles in allow-list discussion; add a brief mention of "token donation" and fediseer or fedibuzz; clarify RSS discussion;
July 20: add paragraph about new threat vectors from trust and safety services, link to "threaderation" suggestion.
July 7: added the top paragraph in response to excellent feedback that a summary would be very helpful! Reworked recommendations.
July 6: many small changes in response to excellent feedback. More specific thanks and acknowledgments coming soon!
July 5: first draft published
July 2-4: early partial drafts sent to "friendlies" for feedback. Because, y'know what else do people have to do on a holiday weekend? So I greatly appreciate everybody who took the time to read it and respond, thank you thank you thank you!